suivant: Interpolation avec calcul au monter: Interpolation de points de précédent: Interpolation avec précalcul du Table des matières
Méthode accélérée
Principe
Afin d'augmenter la rapidité de l'affichage et d'améliorer la qualité visuelle, nous avons tiré parti des capacités de calcul et de filtrage de texture de la carte graphique.
Pour cela, nous affichons un polygone occupant tout l'écran pour lequel la couleur de chaque pixel est calculée par une version modifiée de l'algorithme. En activant l'interpolation bilinéaire de texture, nous lissons ainsi l'image obtenue. De plus, nous pouvons tirer parti du tampon de profondeur de la carte graphique.
Problématique
Néanmoins, l'algorithme doit être modifié. En effet, le problème est
inversé en ce sens que nous devons, étant donné un pixel de coordonnées
![]() affiché, trouver son pixel d'origine dans les images de référence.
Autrement dit, nous devons, pour un instant
affiché, trouver son pixel d'origine dans les images de référence.
Autrement dit, nous devons, pour un instant ![]() donné, connaître
le pixel de chaque image de référence se projetant en
donné, connaître
le pixel de chaque image de référence se projetant en ![]() . Cette
contrainte provient du fait que le programme exécuté par la carte
graphique lors de l'affichage d'un pixel (pixel shader) ne
peut pas afficher un pixel à une position quelconque de l'écran :
le shader est un programme qui ne fait que calculer la couleur
(et la profondeur) d'un pixel en cours d'affichage. Le pixel calculé
est affiché à l'écran à la position actuelle de rastérisation, sans
possibilité de choix.
. Cette
contrainte provient du fait que le programme exécuté par la carte
graphique lors de l'affichage d'un pixel (pixel shader) ne
peut pas afficher un pixel à une position quelconque de l'écran :
le shader est un programme qui ne fait que calculer la couleur
(et la profondeur) d'un pixel en cours d'affichage. Le pixel calculé
est affiché à l'écran à la position actuelle de rastérisation, sans
possibilité de choix.
Réalisation
Pour pouvoir connaître ces deux pixels d'origine nous associons à
chaque point de vue de référence une nouvelle texture qui stocke en
chaque texel les coordonnées 2D du point de l'image de référence qui
s'y projete à un instant ![]() donné, soit
donné, soit
![]() ,
, ![]()
![]() ,
, ![]() = définition de la texture (carrée). Ce précalcul
est effectué par le processeur central, avec un tampon de profondeur
logiciel.
= définition de la texture (carrée). Ce précalcul
est effectué par le processeur central, avec un tampon de profondeur
logiciel.
Le rendu s'effectue en affichant deux fois le polygone occupant tout l'écran : une passe par point de vue. Pour un passage, l'algorithme, codé dans le Pixel Shader de la carte, est le suivant :
- lors de l'affichage d'un pixel
 on obtient le pixel
on obtient le pixel 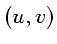 de l'image de référence
de l'image de référence 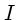 s'y projetant à l'aide de la texture
de déplacement, soit :
s'y projetant à l'aide de la texture
de déplacement, soit :
 .
.
- La profondeur de ce pixel est stockée dans la texture de profondeur
du point de vue de référence, soit :
 .
.
- Reste à exprimer cette profondeur dans l'espace du point de vue virtuel,
soit :
 (reprojection).
(reprojection).
- Finalement, nous affichons le pixel avec la couleur
 et la
profondeur
et la
profondeur  calculée.
calculée.
Résultats
Le résultat de cette méthode est présenté en figure 2.14, ligne du bas. Comme on peut le voir, certains trous dus aux parties sous échantillonnnées de l'image sont efficacement comblés.
La taille de la structure est de 1,25Mo par point de vue de référence pour une définition de 512x512 pixels. Les opérations effectuées par le processeur central sont la génération des textures de déplacement nécessitant la gestion d'un tampon de profondeur logiciel. Tout le reste est effectué par la carte graphique. Malgré une meilleure qualité visuelle, la réduction de l'espace mémoire nécessaire (de plus de moitié) et un taux d'affichage supérieur (>40 FPS avec une GeForceFx et un Athlon 1.4Ghz), la partie CPU de l'algorithme correspond au goulot d'étranglement.
suivant: Interpolation avec calcul au monter: Interpolation de points de précédent: Interpolation avec précalcul du Table des matières